MySQL Full-Text Ngram Parser (1)
MySQL Full-Text Ngram Parser (1)
MySQL ngram parser 기본 개념 및 사용법
MySQL의 Full-Text Ngram Parser는 텍스트 데이터를 효율적으로 검색하기 위해 사용되는 내장 파서로, 특히 한국어, 일본어, 중국어(CJK)와 같은 언어에서 강력한 성능을 발휘합니다. 이는 단어를 고정된 크기의 문자 시퀀스(ngram)로 분해하여 검색을 수행합니다.
주요 특징
- N-gram 방식
- 문자열을 \(n\)개의 문자로 이루어진 연속적인 시퀀스로 분해합니다.
- 예를 들어, “abcd”라는 문자열이 있을 때, 2-gram으로 분해하면 “ab”, “bc”, “cd”와 같은 토큰이 생성됩니다
- 기본적으로 \(n\)값은 2로 설정되어 있으며, 필요에 따라 조정 가능합니다
- 한국어(CJK) 지원
- 공백이나 단어 구분자가 없는 언어(예: 한국어)의 특성을 고려하여 설계되었습니다.
- 예를 들어, “서울특별시”를 2-gram으로 처리하면 “서울”, “울특”, “특별”, “별시”로 분해됩니다
- 내장형 파서
- MySQL에 기본적으로 포함되어 있어 별도의 설치가 필요 없습니다.
- InnoDB와 MyISAM 스토리지 엔진에서 지원됩니다
사용 방법
- Ngram Token Size 확인 및 설정
- 기본값 확인
1
SHOW GLOBAL VARIABLES LIKE 'ngram_token_size';
- 서버 시작 시 \(n\)값 변경
1
mysqld --ngram_token_size=3
- 기본값 확인
- Full-Text Index 생성
- 테이블 생성 시
1 2 3 4 5
CREATE TABLE example ( id INT AUTO_INCREMENT PRIMARY KEY, text_column TEXT NOT NULL, FULLTEXT INDEX ft_index (text_column) WITH PARSER ngram );
- 기존 테이블에 추가
1
ALTER TABLE example ADD FULLTEXT INDEX ft_index (text_column) WITH PARSER ngram;
- 테이블 생성 시
- 검색 쿼리
- 기본 검색
1
SELECT * FROM example WHERE MATCH(text_column) AGAINST('검색어');
- 정확한 검색(IN BOOLEAN MODE)
1
SELECT * FROM example WHERE MATCH(text_column) AGAINST('검색어' IN BOOLEAN MODE);
- 기본 검색
장점
- 효율적인 검색: 긴 문장에서 특정 단어나 패턴을 빠르게 찾을 수 있습니다.
- LIKE 연산자 대체: 느린
%검색어%와 같은 패턴 매칭 대신 Full-Text Index를 사용하여 성능을 향상시킵니다. - 다양한 언어 지원: CJK 언어의 복잡한 구문 구조에서도 높은 검색 정확도를 제공합니다.
MySQL Ngram Parser는 특히 한국어와 같은 언어에서 정밀하고 빠른 텍스트 검색을 가능하게 하며, Full-Text Index와 결합하여 높은 성능을 제공합니다.
테스트용 테이블 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
-- 테스트용 테이블 생성
CREATE TABLE test_ngram (
id INT PRIMARY KEY,
content TEXT,
FULLTEXT INDEX ngram_idx (content) WITH PARSER ngram
);
-- 데이터 삽입
INSERT INTO test_ngram VALUES (1, '안녕하세요');
-- 토큰화된 결과 확인 위해 글로벌 변수 설정
-- 캐시 모니터링 활성화
SET GLOBAL innodb_ft_aux_table = 'database_name/table_name';
-- 실제 토큰화된 결과 확인 (MySQL 8.0 이상)
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE;
“안녕하세요”를 1-gram으로 토큰화한 결과는 다음과 같습니다.
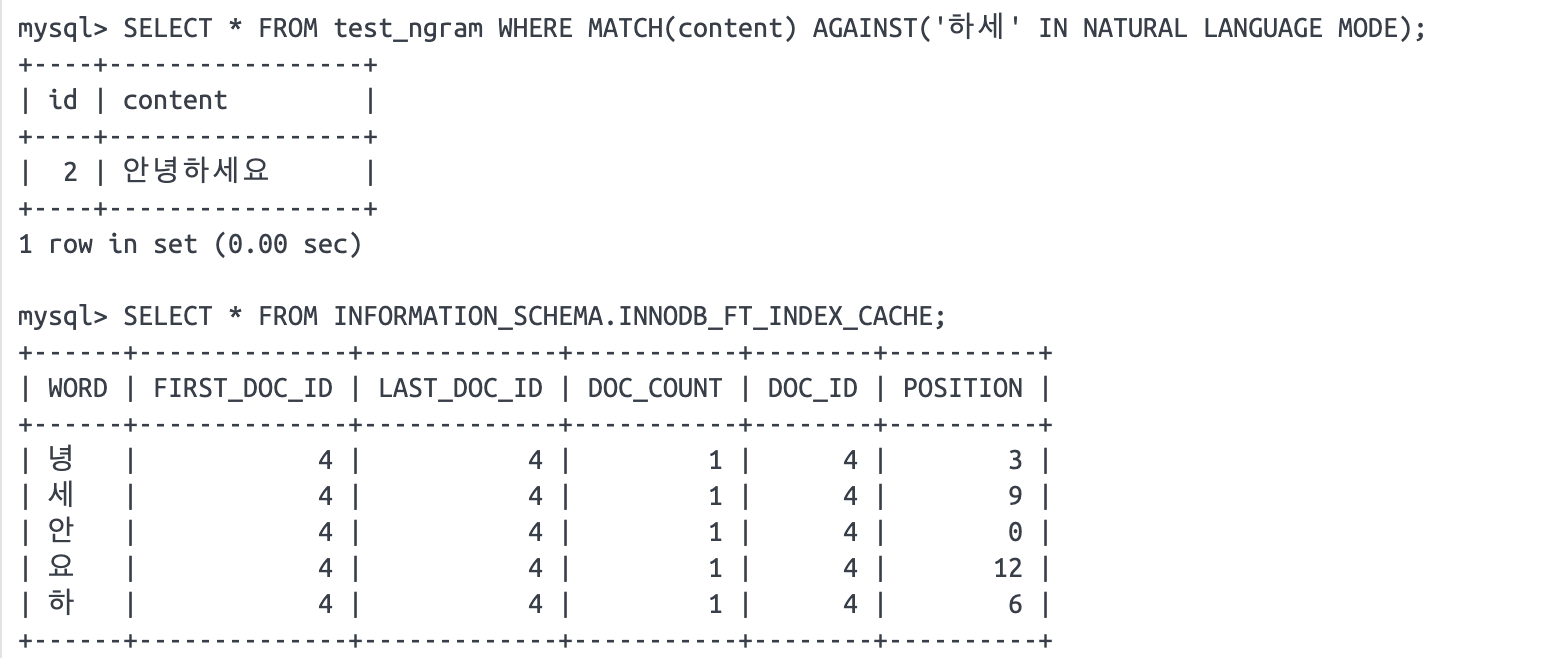
“안녕하세요”인 content가 또 한번 더 들어갔을 때 결과
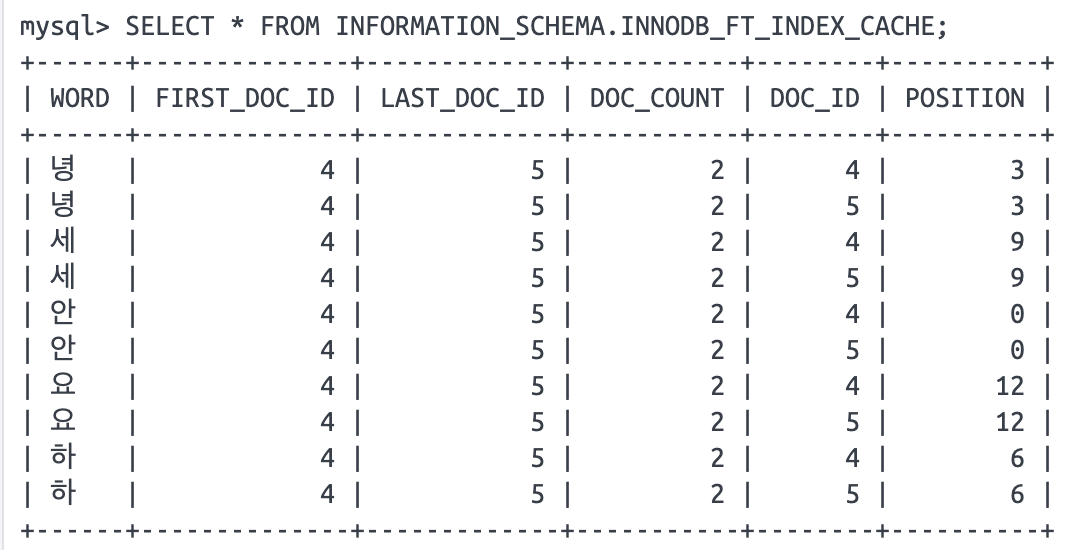
여기까지는 인터넷에 나온 내용을 정리한 것이고, 다음은 MySQL 소스 코드를 분석하면서 ngram parser의 동작 원리와 각 행이 무슨 의미인지 알아보겠습니다.
This post is licensed under CC BY 4.0 by the author.