MySQL Full-Text Ngram Parser (2)
ngram parser
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
while (next < end) {
char_len = my_mbcharlen_ptr(cs, next, end);
/* Skip the rest of the doc if invalid char. */
if (next + char_len > end || char_len == 0) {
break;
} else {
/* Skip SPACE or ","/"." etc as they are not words*/
/*
" " -> 공백 (건너뜀)
"," -> 쉼표 (건너뜀)
"." -> 마침표 (건너뜀)
"!" -> 느낌표 (건너뜀)
*/
int ctype;
cs->cset->ctype(cs, &ctype, (uchar *)next, (uchar *)end);
if (char_len == 1 && (*next == ' ' || !true_word_char(ctype, *next))) {
start = next + 1;
next = start;
n_chars = 0;
continue;
}
전달한 문장에 대해 하나씩 읽을때, 유효하지 않은 단어들은 넘어간다.
1
2
3
4
5
6
7
8
9
10
11
if (n_chars == ngram_token_size) {
/* Add a ngram */
bool_info->position = start - doc;
ret = param->mysql_add_word(param, start, next - start, bool_info);
RETURN_IF_ERROR(ret);
/* Move a char forward */
start += my_mbcharlen_ptr(cs, start, end);
n_chars = ngram_token_size - 1;
is_first = false;
}
읽은 문자가 설정한 토큰 개수와 같다면, ngram을 추가한다.
mysql_add_word 는 파서가 찾아낸 각각의 토큰(단어)을 MySQL의 FULLTEXT 인덱스 시스템에 전달하는 역할을 한다.
- 토큰 처리
1
2
3
4
5
// 예: "안녕하세요"에서 2-gram으로 처리할 경우
mysql_add_word(param, "안녕", 6, bool_info); // UTF-8에서 한글 2글자는 6바이트
mysql_add_word(param, "녕하", 6, bool_info);
mysql_add_word(param, "하세", 6, bool_info);
mysql_add_word(param, "세요", 6, bool_info);
인덱스 저장
- 각 토큰은 InnoDB의 특별한 인덱스 테이블에 저장됨
- 토큰과 함께 원본 문서의 ID도 저장
- 나중에 검색할 때 이 인덱스를 사용
토큰은 어떻게 분할하는 지 알겠으니, 이제 FULLTEXT 인덱스 시스템에 전달하고 저장하는 부분을 알아봐야겠다.
인덱스 테이블 구조
fts_tokenize_add_word_for_parser 함수가 mysql_add_word MySQL의 FTS 파서 플러그인 인터페이스에서 정의된 콜백 함수의 실제 InnoDB 구현체이다.
코드를 살펴보면 fts_add_token 함수를 호출하는 것을 볼 수 있다.
fts_add_token 함수는 토큰을 인덱싱하는 핵심 함수이다.
1. 토큰 유효성 확인
1
if (fts_check_token(&str, nullptr, result_doc->is_ngram, result_doc->charset))
N-gram 모드인 경우, 별도의 검증 로직이 적용되고, 불용어 체크가 수행된다.
2. 토큰 문자열 준비
1
2
t_str.f_len = str.f_len * result_doc->charset->casedn_multiply + 1;
t_str.f_str = static_cast<byte *>(mem_heap_alloc(heap, t_str.f_len));
초기 스택의 임시 버퍼를 사용한 토큰은, 힙 메모리에 복사하기 위해 새로운 메모리를 할당한다.
3. Red-Black 트리 구조로 토큰 저장
1
2
3
4
5
6
7
8
if (rbt_search(result_doc->tokens, &parent, &t_str) != 0) {
// 새로운 토큰 생성
new_token.positions = ib_vector_create(...);
parent.last = rbt_add_node(result_doc->tokens, &parent, &new_token);
}
// 위치 정보 추가
token = rbt_value(fts_token_t, parent.last);
ib_vector_push(token->positions, &position);
Red-Black 트리에서 토큰을 검색하고, 없으면 토큰을 새로 생성하고 토큰의 문서 내 위치 정보를 저장한다.
말이 어려운데, 예를 들어 “hello world hello” 문장을 처리한다면
hello 첫번째 등장하면
1
2
3
// rbt_search에서 "hello" 못찾음 (!=0 반환)
new_token = {"hello", positions=[0]} // 위치 0에서 발견
rbt_add_node(tokens, new_token) // R-B 트리에 추가
그다음 world 등장하면
1
2
3
// rbt_search에서 "world" 못찾음
new_token = {"world", positions=[6]} // 위치 6에서 발견
rbt_add_node(tokens, new_token) // R-B 트리에 추가
hello 두번째 등장하면
1
2
3
4
// rbt_search에서 "hello" 찾음 (=0 반환)
token = {"hello", positions=[0]} // 기존 토큰 가져옴
ib_vector_push(positions, 12) // 위치 12 추가
// 결과: {"hello", positions=[0,12]}
이렇게 키는 토큰 문자열 값은 토큰 정보(위치 정보)를 가지는 구조로 R-B 트리 형태로 메모리에 저장된다.
R-B 트리를 사용한 이유는 뭘까? 아마도 균형 이진 트리를 사용해서 메모리를 아끼고, 최악의 경우에도 삽입과 탐색 모두 O(log n)의 시간 복잡도를 보장하기 위해서일 것이다.
검색이 빠른 진짜 이유는 역인덱스 형태
캐시의 R-B 트리는 여러 문서의 토큰들을 모두 저장하는 역인덱스 구조이다.
역인덱스란, 토큰을 키로 하고, 해당 토큰이 포함된 문서의 ID를 값으로 하는 구조이다.
예를들어, “안녕하세요” 문서가 1번 문서에 포함되고, “안녕”이 2번 문서에 포함되고 ngram 파서로 토큰 2-gram으로 처리한다면, 아래와 같은 그림이 표현될 수도 있을 것 같다.
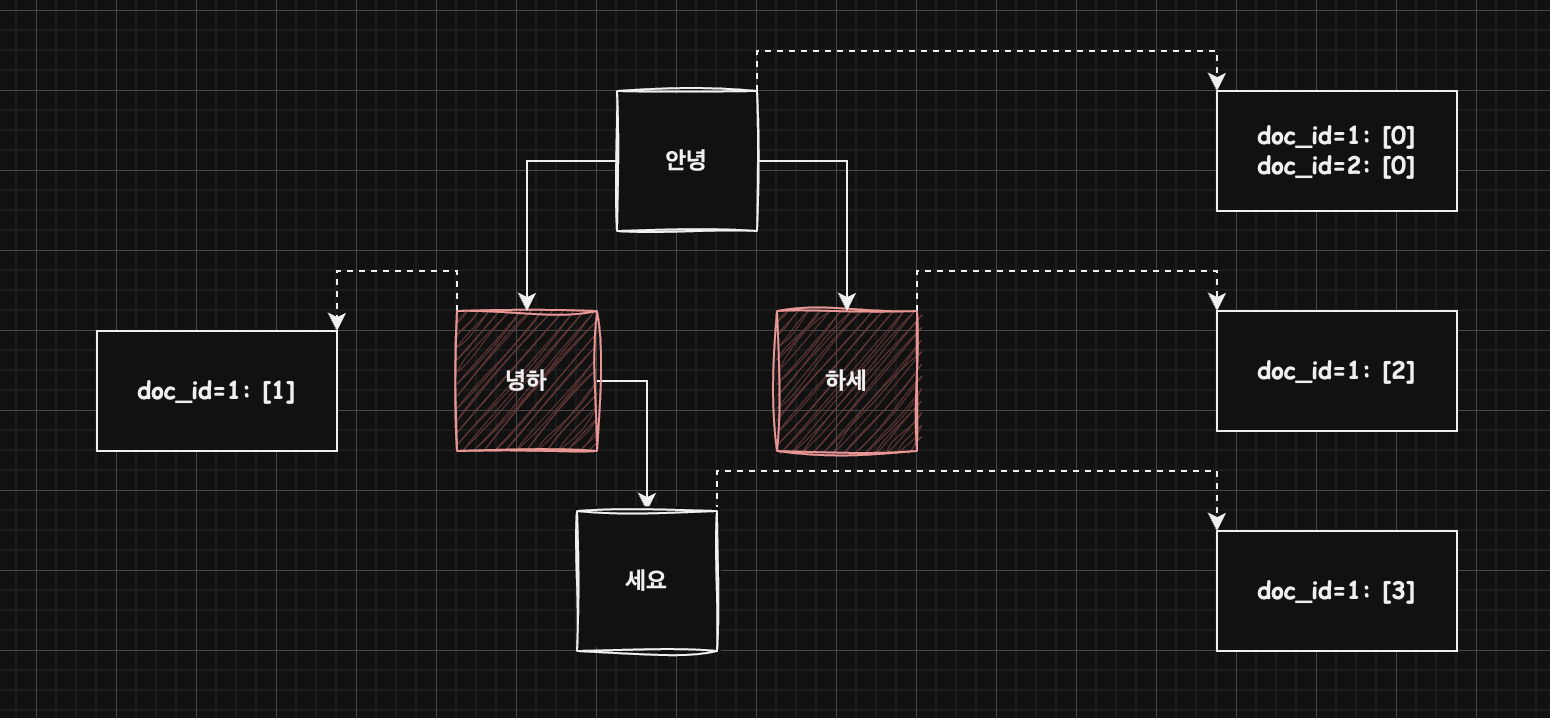
만들어진 R-B 트리는 바로바로 디스크에 저장되는가?
아니다. 공식문서에 따르면, 문서가 삽입될 때마다 토큰화되어 전문 인덱스에 들어가야 하는데, 이 과정에서 보조 인덱스 테이블에 많은 소규모 삽입이 발생한다.
이런 빈번한 삽입은 동시성 문제(테이블 경합)를 일으킬 수 있기 때문에, InnoDB는 full-text index cache를 사용한다. 새로 삽인된 행의 인덱스 데이터를 메모리 캐시에 임시 저장하고 캐시가 가득 차면 일괄적으로 (batch) 디스크에 플러시한다.
InnoDB의 FTS(Full-Text Search) 캐시의 실제 구조체는 fts_cache_t이다. 해당 링크에서 자세한 내용을 확인할 수 있다.
이 구조체는 전문 검색을 위한 인메모리 역인덱스를 구현하면서, 동시성 제어와 메모리 관리를 포함한 완전한 캐시 시스템을 제공하고 있다.
캐시 사이즈도 중요한데, 최근에 대량의 데이터를 한번에 인덱싱하다가 캐시가 가득 차서 더 이상 새 토큰을 저장할 수 없는 경우가 있었다.
이런 경우에는 innodb_ft_cache_size 설정값을 늘려주면 된다.
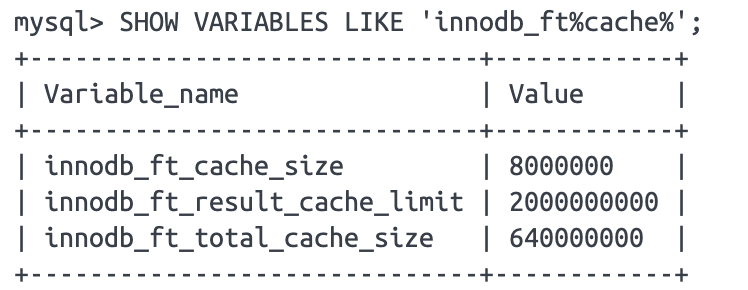
지금 캐시 사이즈는 8MB로 설정되어 있는데, 이 값을 늘리면 더 많은 토큰을 캐싱할 수 있게 된다. 명령어는 SET GLOBAL innodb_ft_cache_size = 16 * 1024 * 1024; 이런식으로 설정하면 된다.
번외로, 검색 인덱스를 구축할 때 InnoDB FULLTEXT 인덱스의 텍스트를 인덱스하고 토큰화하기 위해 병렬로 사용되는 스레드 수도 설정할 수 있다. 다음을 참고하자 innodb
캐시의 역인덱스 내용이 디스크의 fts 인덱스 테이블로 영구 저장되는 과정
1
2
3
if (cache->total_size > fts_max_cache_size / 5 || fts_need_sync) {
fts_sync(cache->sync, true, false, false);
}
새로운 문서가 추가될 때마다 캐시 크기가 임계값을 초과하는지 체크하고, 또는 명시적 동기화 요청이 있는지 체크한다. 조건이 만족되면 캐시를 디스크로 동기화한다.
동기화 과정은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
// token: 검색할 단어
pars_info_bind_varchar_literal(info, "token", word->f_str, word->f_len);
// 해당 단어가 있는 문서 범위
fts_bind_doc_id(info, "first_doc_id", &first_doc_id);
fts_bind_doc_id(info, "last_doc_id", &last_doc_id);
// 문서 수
pars_info_bind_int4_literal(info, "doc_count", &doc_count);
// 위치 정보 리스트
pars_info_bind_literal(info, "ilist", node->ilist, node->ilist_size, ...);
SQL 바인딩을 하는 과정이다
1
2
INSERT INTO $index_table_name VALUES
(:token, :first_doc_id, :last_doc_id, :doc_count, :ilist);
FTS 인덱스 테이블에 INSERT 쿼리를 실행한다.
이제 전체적인 흐름을 다음 장에서 정리해보겠다.