MySQL Full-Text Ngram Parser (3)
MySQL Full-Text Ngram Parser (3)
Step1. ngram parser로 문서 토큰화

- 문서 텍스트를 n-gram 단위로 분리
- N-gram Parser가 각 토큰을 생성
- 각 토큰의 문서 내 위치 정보 기록
Step2. 메모리 캐시 단계 (FTS 캐시)
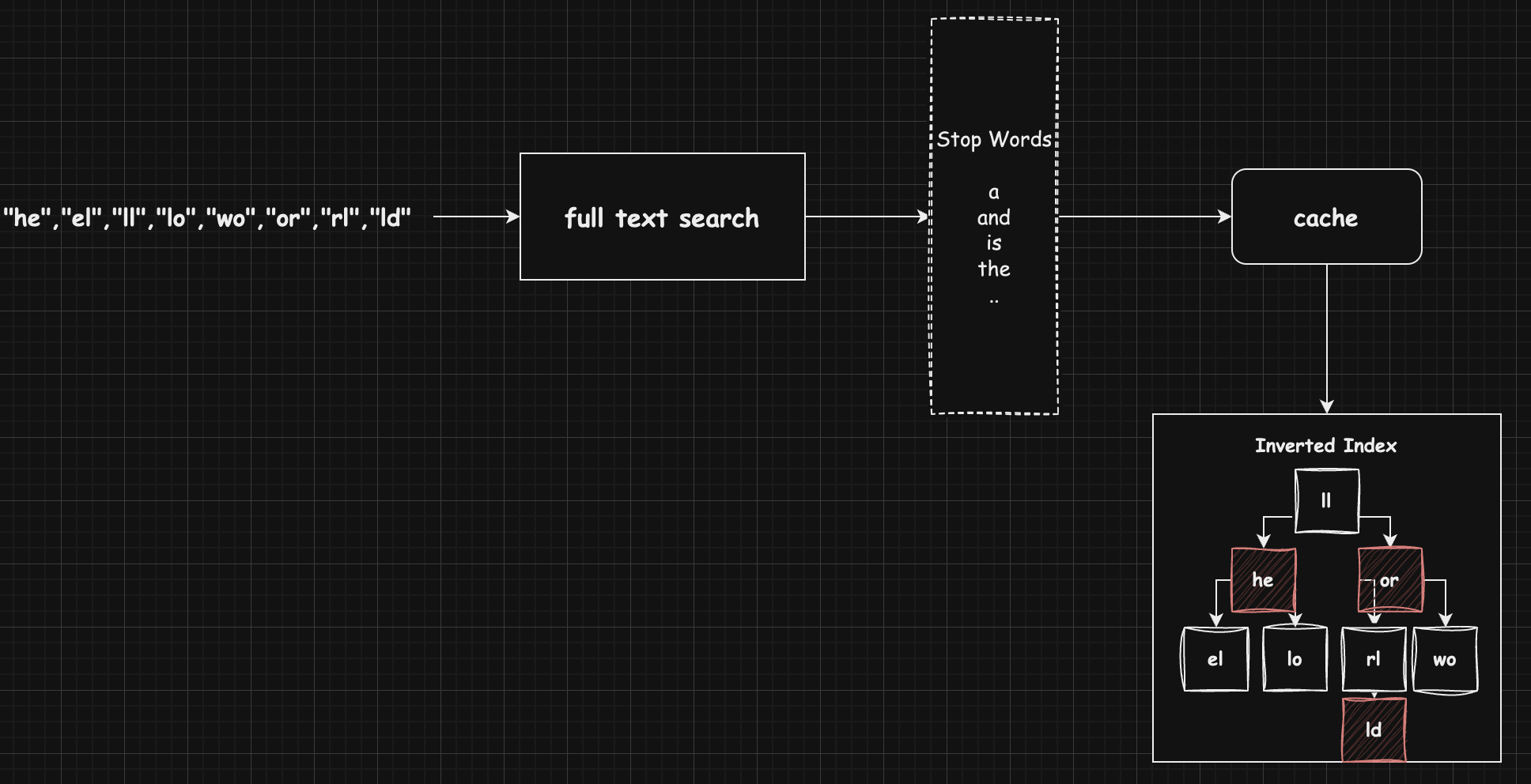
- 생성된 토큰을 R-B 트리에 저장
- 각 토큰마다 문서 ID와 위치 정보를 역인덱스 형태로 관리
- 같은 토큰이 이미 있다면 해당 토큰의 문서/위치 정보만 추가
Step3. 캐시 -> 디스크 동기화 단계
캐시 크기가 임계값 초과하거나 명시적 SYNC 요청이 있을 때 캐시의 R-B 트리 내용을 FTS 인덱스 테이블로 변환한다.
각 토큰은 토큰문자열, 첫 문서 ID, 마지막 문서 ID, 압축된 위치 정보 리스트 등으로 구성하고 INSERT 한다.
검색과정
1) 검색어를 n-gram 단위로 분리
1
2
3
// 검색어를 N-gram으로 분리
// 예: "안녕하세요" -> "안녕", "녕하", "하세", "세요"
fts_tokenize_document(&doc, nullptr, parser);
2) 캐시 검색
1
2
// 먼저 메모리 캐시의 R-B 트리에서 각 토큰 검색
fts_cache_find_token(cache, token);
3) 디스크 검색
1
2
3
4
// 캐시에 없는 토큰은 FTS 인덱스 테이블에서 검색
// SELECT * FROM FTS_INDEX_TABLE
// WHERE token = :search_token
fts_table_fetch_doc_ids(trx, table, token);
4) 결과 집합 처리
1
2
3
4
5
// 여러 토큰의 검색 결과를 조합
// - AND 검색: 교집합
// - OR 검색: 합집합
// - 근접 검색: 위치 정보 활용
fts_query_process_word(...);
5) 랭킹 및 정렬
1
2
3
4
5
// 관련성 점수 계산
// - 문서 내 출현 빈도
// - 위치 정보
// - 기타 랭킹 요소
fts_rank_result(...);
마무리
예전에 500만건의 도서데이터를 추가하고 각 책 이름은 “BOOK-0000001”, “BOOK-0000002”, … 형태로 저장했었다. 이때 “20”이라는 검색어를 입력하면 카운트쿼리가 제대로 나오지않고, 느리게 나왔다.
이유는 full text 인덱스를 ngram 파서를 이용해 토큰은 1글자로 분리해서 만들었고, 이때 “20*“이라는 검색어는 “2”, “0”으로 분리되어 인덱싱되었기 때문이다.
“2”라는 데이터는 약 2만건이어었고, 인덱스테이블에서 r-b 트리를 거쳐서 “2”라는 토큰을 찾고 2만건의 문서 ID를 가져온다. 그리고서 이 2만건의 실제 데이터를 조회하는 두번째 I/O가 발생한다. 그런데 이 DOC_ID는 연속적이지 않기 때문에 랜덤 I/O가 발생하고, 이로 인해 느린 검색이 발생했다.
이런문제는 더미데이터가 아닌 실제 데이터에선 문제가 생기지 않고, 토큰은 1글자 보다는 2글자 이상으로 분리하는 것이 좋을 것 같다.
This post is licensed under CC BY 4.0 by the author.